[post-views]
國立高雄科技大學
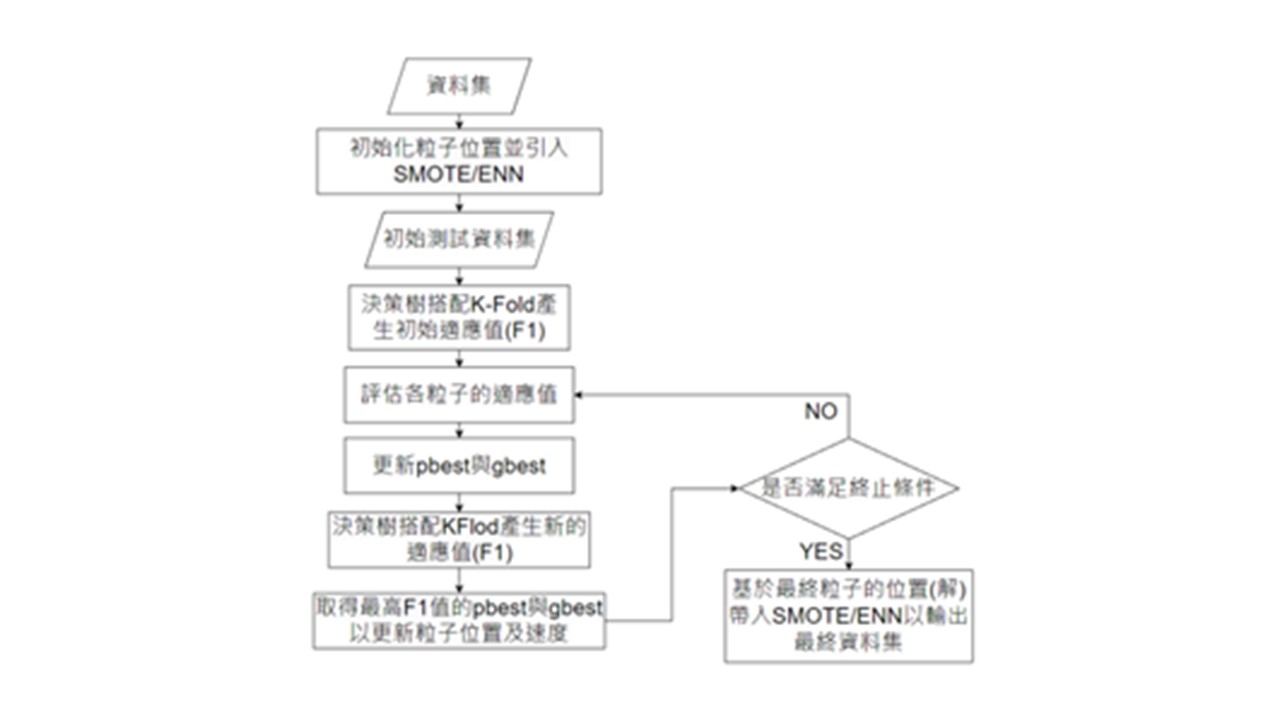
不平衡資料分類是在許多實際上的應用中常見的問題。當其中一個種類的實例數量遠少於另一種類時,便可能導致訓練模型出現偏差,對於預測少數類別的結果會相對較差。在過去提出各種技 術來解決這個問題,例如針對多數類進行減少的欠採樣(Under-sampling)方法,還有對少數類進行過採樣(Over-sampling)的方法。
研究中提出的方法使用公開資料集KEEL來進行測試並與其他幾種較為常見的採樣方法進行比較,其中會以 F1、G-MEAN 等幾種評估分數來測試,測試為在資料集中隨機提取24種類別並分開運行,而使用啟發式最佳化演算法混合採樣的好處就是,在取得最佳成結果之前需要人為處理的部分會減輕,只須設定好初始參數就行,不需要不斷手動調整以達最佳成果。
單位:電子工程系
研究領域:物聯網、資訊安全、電腦網路、復健輔具開發、產業數位轉型
學術專長:嵌入式系統軟體設計技術、人工智慧技術、感測網路技術
高等資通訊技術實驗室
本團隊的主要研究方向有人工智慧與深度學習研發應用、嵌入式AI系統以及網路安全分析技術,期望能與業界共同合作,帶領學生投入產業實務技術研究,累積實務研發經驗。
研究領域:資訊安全、啟發式演算法
學術專長:無線通信、電腦網路、嵌入式系統
專長:資訊安全、深度學習、 開集識別
研究方向:未知分散式服務阻斷攻擊偵測
專長:機器學習、啟發式演算法
研究方向:透過狼群搜索找到不平衡資料集的最佳採樣模式
專長:嵌入式系統 (RTOS)、微控制器、Linux架站、版本管理
研究方向:體感健身、冷鍊物流追蹤、智慧農業
專長:機器學習、Python、MCU語言、股票技術分析
研究方向:系統整合、選股系統、資料探勘
專長:Python、機器學習
研究方向:人工智慧、自然語言處理、資料擴增
國立高雄科技大學 學研單位








{kind=link}